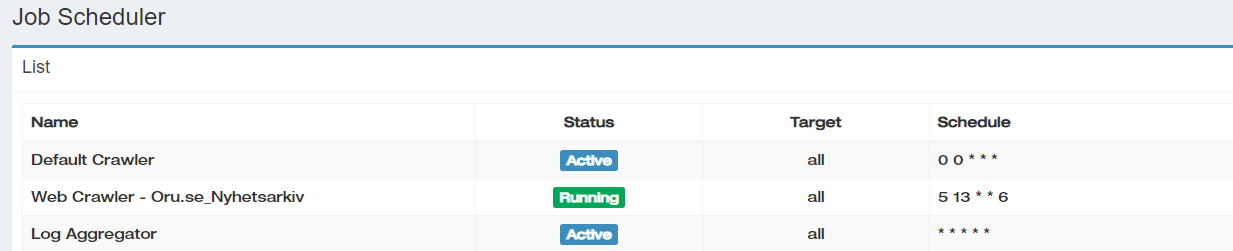
Hi!
I have created one new scheduled job called Web Crawler - Oru.se_Nyhetsarkiv that starts the new crawl called Oru.se_Nyhetsarkiv. How do I set the default crawler to NOT start that crawl and only the other two called Inforum and Oru_se?
There is a setting called Target wich now has All. Can I put the crawl ID:s there? How would the syntax look like?
Please uncheck the status for Default Crawler on the Scheduler page.
- I want the
default crawler job to start two crawls (Inforum and Oru_se) each night.
- I want the crawler job
Web Crawler - Oru.se_Nyhetsarkiv to start the crawl Oru.se_Nyhetsarkiv each saturday (as you see in Schedule).
The default crawler Script is: return container.getComponent("crawlJob").logLevel("info").gcLogging().execute(executor);
How do I set it to only start Inforum ID: 6gU6cGsBOSEUn5yAve7V and Oru_se ID: 6QU5cGsBOSEUn5yAhe7l?
What is the meaning of Target: all? What values can you put instead of all?
I think the script of the default crawler is as follows:
return container.getComponent("crawlJob").logLevel("info").gcLogging().webConfigIds("6gU6cGsBOSEUn5yAve7V","6QU5cGsBOSEUn5yAhe7l").execute(executor);
Target is a setting for a cluster configuration.