Hi,
I have some troubles to crawl some files. I am using the latest version of fess, which is 14.16.0 with opensearch 2.16.0 on a Win11 PC
Originally I wanted to crawl/index some files from a test directory on my NAS, but it said “INFO Processing no docs in indexing queue” etc.
So I tried to copy the folder on my local PC where Fess is running and tried with a new Filesystem-crawler called “Filesystem_test_local”
The folder with all my files(pdf, txt, xlsx etc.) is on “C:\Fess_test_local” so I configured the “Filesystem_test_local”-crawler with the following:
-
ID: bCz3eJEB5jT5m4cO_QC_
-
Name: Filesystem_test_local
-
Paths: file:///C:/Fess_test_local/*
-
Included Paths For Crawling:
file:///C:/Fess_test_local/*
.*/$
.*pdf$
.*txt$
.*xlsx$
.*docx$ -
Included Paths For Indexing:
.*/$
.*pdf$
.*txt$
.*xlsx$
.*docx$
Then I created a Job in the scheduler with the following parameters:
Name: Filesystem_test_local
Target: all
Schedule:
Executor: groovy
Script: return container.getComponent(crawlJob).logLevel(info).webConfigIds( as String).fileConfigIds([bCz3eJEB5jT5m4cO_QC_] as String).dataConfigIds( as String).jobExecutor(executor).execute();
Logging: Enabled
Crawler Job: Enabled
Status: Enabled
Display Order: 0
I started the Job manually and after a short time the Job was Ok, but the Index size in System Info → Crawling Info was 0
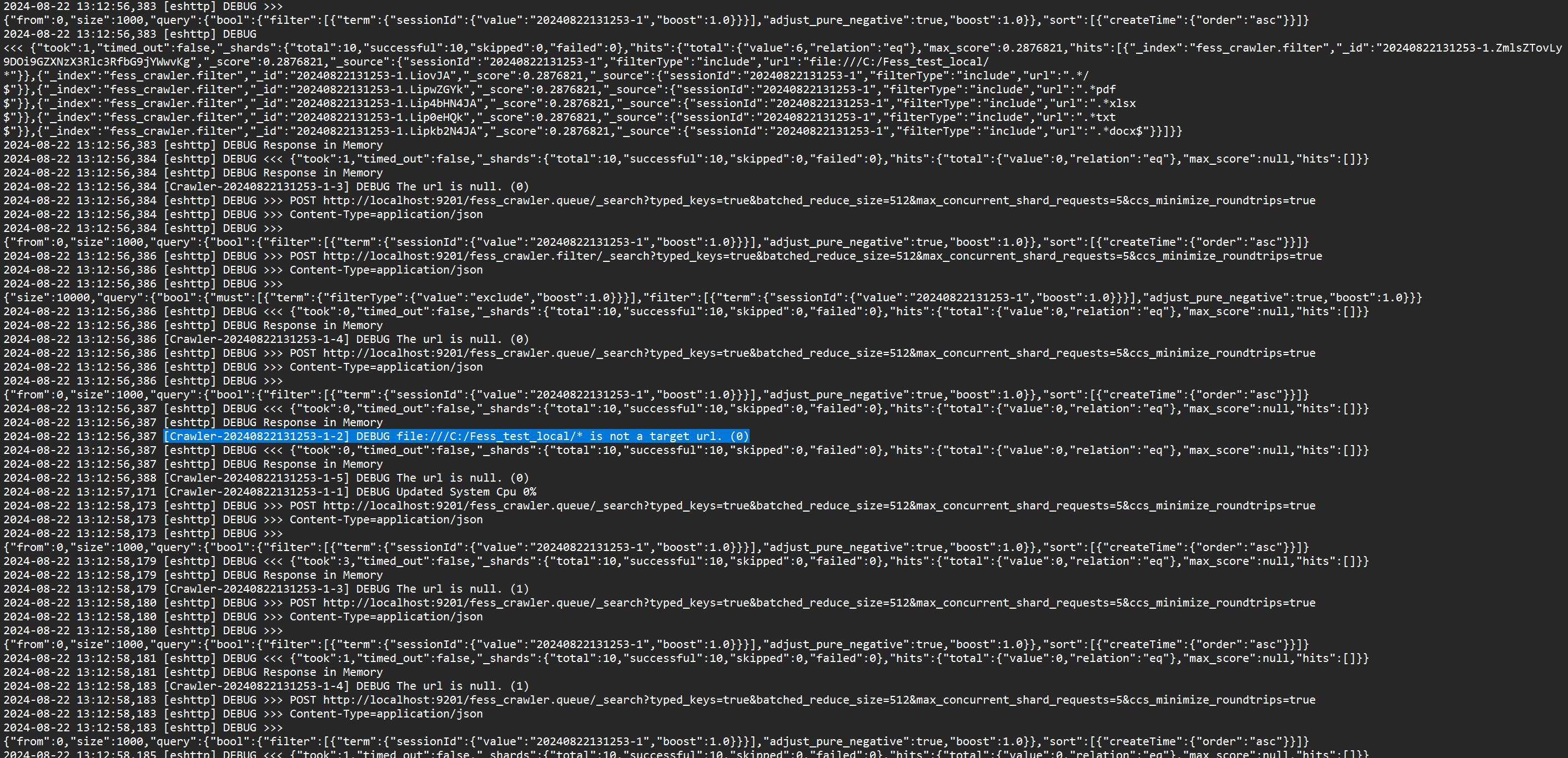
And in the fess-crawler.log I got the following:
2024-08-22 09:52:28,466 [WebFsCrawler] INFO Target Path: file:///C:/Fess_test_local/*
2024-08-22 09:52:28,466 [WebFsCrawler] INFO Included Path: file:///C:/Fess_test_local/*
2024-08-22 09:52:28,466 [WebFsCrawler] INFO Included Path: .*/$
2024-08-22 09:52:28,466 [WebFsCrawler] INFO Included Path: .*pdf$
2024-08-22 09:52:28,467 [WebFsCrawler] INFO Included Path: .*txt$
2024-08-22 09:52:28,467 [WebFsCrawler] INFO Included Path: .*xlsx$
2024-08-22 09:52:28,467 [WebFsCrawler] INFO Included Path: .*docx$
2024-08-22 09:52:38,485 [IndexUpdater] INFO Processing no docs in indexing queue (Doc:{access 6ms}, Mem:{used 144.348MB, heap 372.736MB, max 524.288MB})
2024-08-22 09:52:48,479 [IndexUpdater] INFO Processing no docs in indexing queue (Doc:{access 4ms}, Mem:{used 147.408MB, heap 372.736MB, max 524.288MB})
2024-08-22 09:52:58,481 [IndexUpdater] INFO Processing no docs in indexing queue (Doc:{access 5ms}, Mem:{used 149.831MB, heap 372.736MB, max 524.288MB})
2024-08-22 09:52:58,923 [WebFsCrawler] INFO [EXEC TIME] crawling time: 30518ms
2024-08-22 09:53:08,480 [IndexUpdater] INFO Processing no docs in indexing queue (Doc:{access 2ms}, Mem:{used 149.998MB, heap 372.736MB, max 524.288MB})
2024-08-22 09:53:08,480 [IndexUpdater] INFO [EXEC TIME] index update time: 26ms
2024-08-22 09:53:08,553 [main] INFO Finished Crawler
2024-08-22 09:53:08,599 [main] INFO [CRAWL INFO] CrawlerEndTime=2024-08-22T09:53:08.553+0200,WebFsCrawlExecTime=30518,CrawlerStatus=true,CrawlerStartTime=2024-08-22T09:52:28.385+0200,WebFsCrawlEndTime=2024-08-22T09:53:08.552+0200,WebFsIndexExecTime=26,WebFsIndexSize=0,CrawlerExecTime=40168,WebFsCrawlStartTime=2024-08-22T09:52:28.397+0200
2024-08-22 09:53:08,603 [main] INFO Disconnected to http://localhost:9201
2024-08-22 09:53:08,606 [main] INFO Destroyed LaContainer.
I do not know why he says that “Processing no docs in indexing queue”, since there are files in my Fess_test_local folder and if I go to the Browser and type the URL file:///C:/Fess_test_local/name_of_pdf.pdf I can see a pdf from that folder.