(from github.com/PakanAngel)
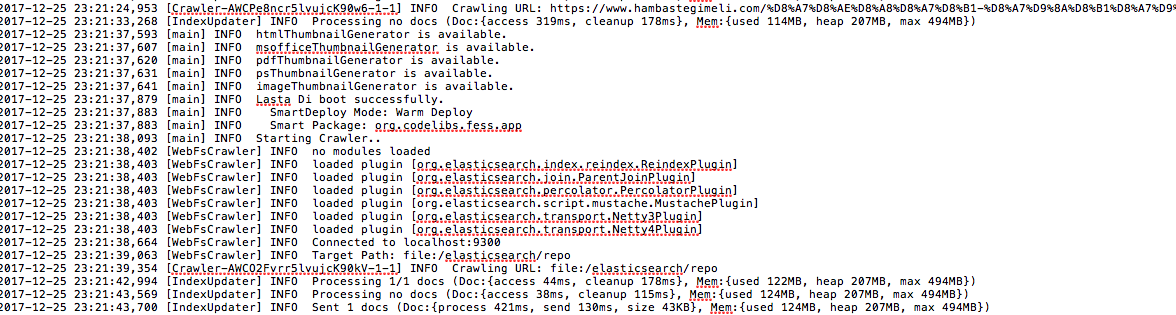
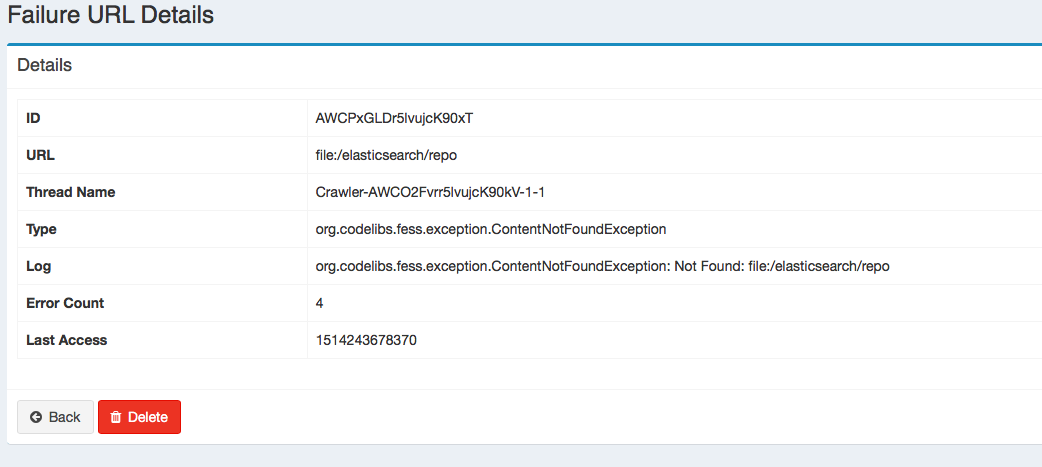
I did configure a Fess file crawler on Centos 7 that didn’t work at all. All files are in PDF format and are in a folder at root: /elasticsearch/repo but the crawler cannot find the folder. After changing some setups on the crawler now when I want to start the job, get the error: Failed to start job File Crawler.
1- Why do I get this message and cannot start the job?
2- What is wrong in my crawler setting that it refuses to index those files?
File Crawler Settings:
Name: Docs
Paths: file:/elasticsearch/repo
Depth: 3
Max Access Count: 1000
The Number of Thread: 1
Interval Time: 1000ms
Boost: 1.0
Permissions: {role}guest
Label: Docs
Status: Enabled
(from github.com/PakanAngel)
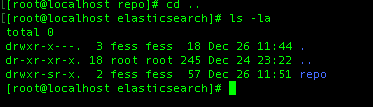
I’ve changed the owner and permission of that folder to “fess” user, but still the same problem.
Can you check my crawler.log file to see what could cause this issue? fess-crawler.log
(from github.com/PakanAngel)
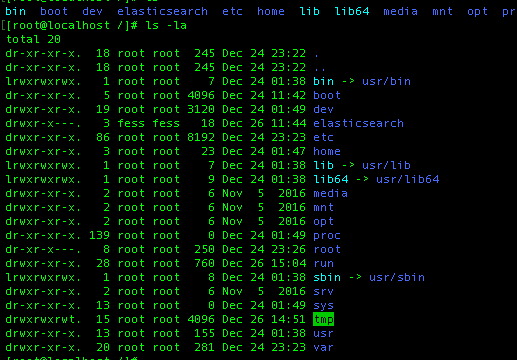
I can also change my repo folder to another folder which Fess can access by default but which folder would be better for this case?
(from github.com/PakanAngel)
Finally solved. But don’t really know what caused the problem. I changed my file crawler folder to /usr/share/fess/bin which is the main Fess folder to see if I can perform any crawling or not. I realized that the crawler works. After a while I changed the crawl path to my initial repo. folder at /elasticsearch/repo/ and suddenly it crawled all files residing there. It is definite that any folder you want to use as a repository for file crawling should be set to fess user.