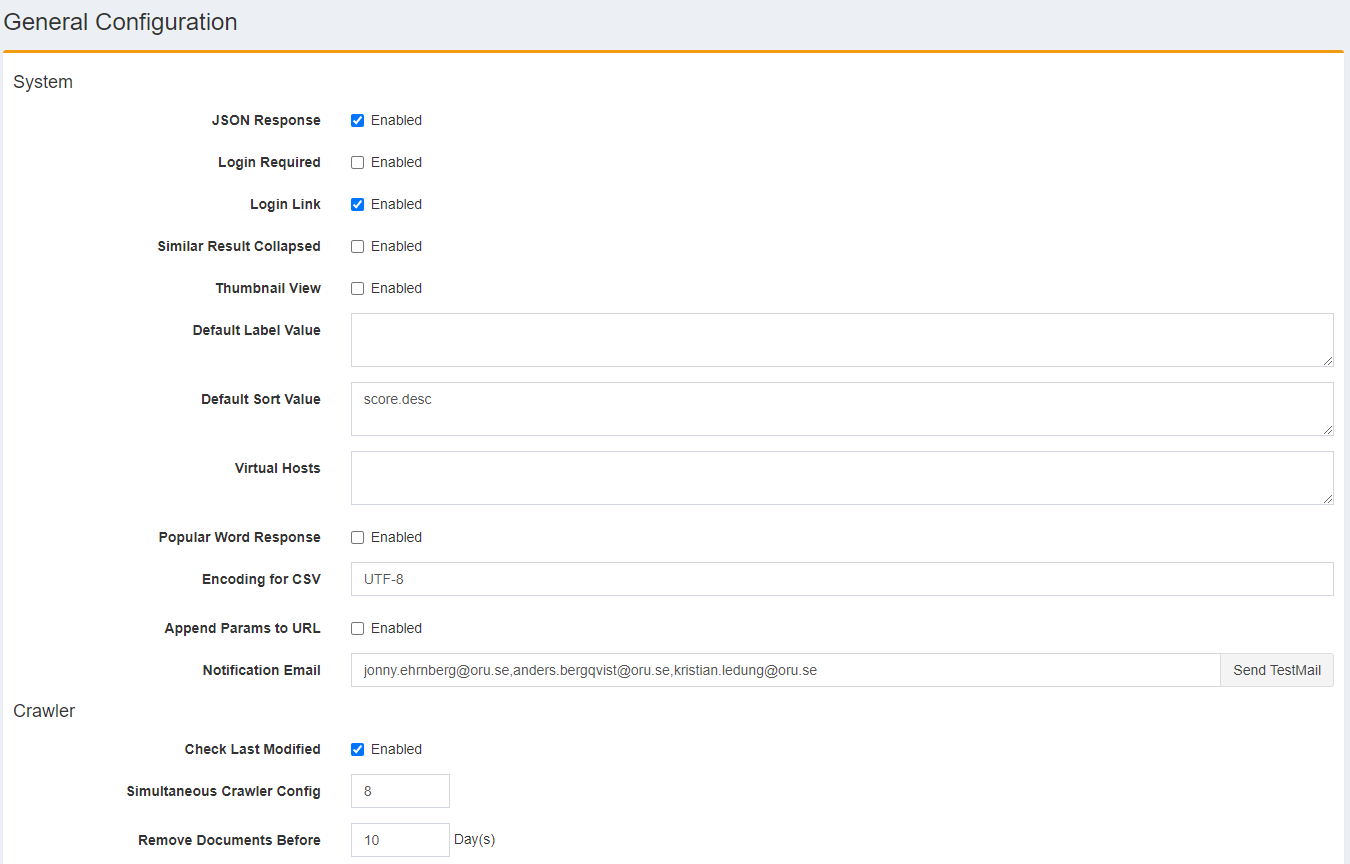
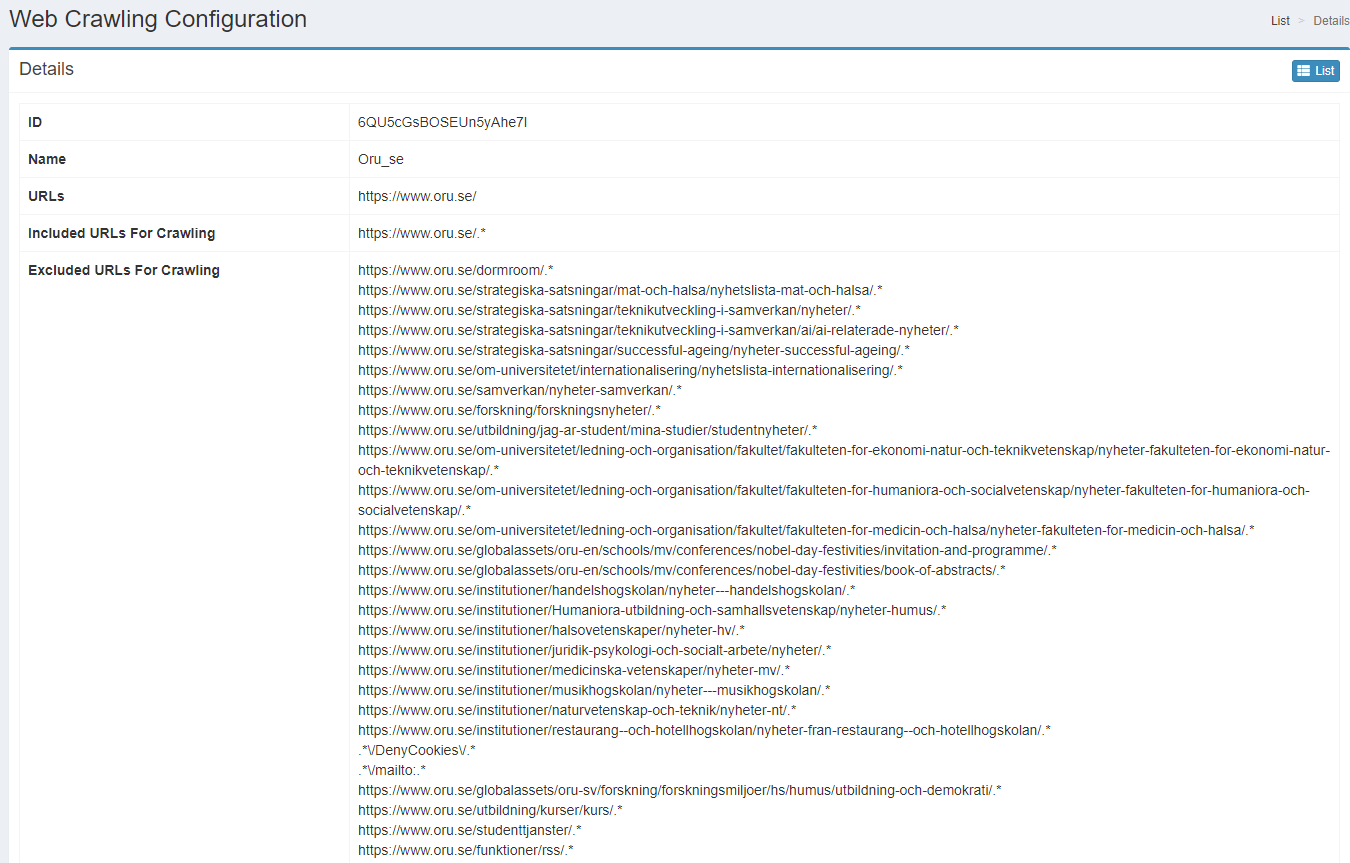
Hi!
I’ve tried to exclude all pages with paging such as https://www.oru.se/english/news/?page=4
I’ve put java regexp in “Excluded URLs For Indexing” and tried:
.*\?page=\d{1,4}$
Is that correct and how can I see if that worked. In crawler.log I can only see “Excluded URL:” and thats the url:s in "Excluded from crawling not excluded from indexing, right?
I also have a problem with no-index in that all those paging url:s turn up over 150 times in each crawl. Why does Fess crawl a noindex- url more than one time each crawl?
Example from a search of one url in crawler.log:
F:\Skrivbordet\fess-crawler.log (382 hits)
Line 49307: 2021-12-08 04:40:27,977 [Crawler-20211208000000-2-4] INFO Crawling URL: https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 49308: 2021-12-08 04:40:28,121 [Crawler-20211208000000-2-4] INFO META(robots=noindex): https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 50590: 2021-12-08 04:46:06,826 [Crawler-20211208000000-2-7] INFO Crawling URL: https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 50591: 2021-12-08 04:46:06,984 [Crawler-20211208000000-2-7] INFO META(robots=noindex): https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 51236: 2021-12-08 04:48:59,341 [Crawler-20211208000000-2-5] INFO Crawling URL: https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 51237: 2021-12-08 04:48:59,493 [Crawler-20211208000000-2-5] INFO META(robots=noindex): https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 51917: 2021-12-08 04:51:59,819 [Crawler-20211208000000-2-1] INFO Crawling URL: https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 51919: 2021-12-08 04:51:59,957 [Crawler-20211208000000-2-1] INFO META(robots=noindex): https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 52643: 2021-12-08 04:55:11,056 [Crawler-20211208000000-2-1] INFO Crawling URL: https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 52644: 2021-12-08 04:55:11,205 [Crawler-20211208000000-2-1] INFO META(robots=noindex): https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 53404: 2021-12-08 04:58:30,004 [Crawler-20211208000000-2-8] INFO Crawling URL: https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 53406: 2021-12-08 04:58:30,153 [Crawler-20211208000000-2-8] INFO META(robots=noindex): https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 54183: 2021-12-08 05:01:57,121 [Crawler-20211208000000-2-3] INFO Crawling URL: https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 54186: 2021-12-08 05:01:57,966 [Crawler-20211208000000-2-3] INFO META(robots=noindex): https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 54967: 2021-12-08 05:05:20,998 [Crawler-20211208000000-2-1] INFO Crawling URL: https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
Line 54969: 2021-12-08 05:05:21,180 [Crawler-20211208000000-2-1] INFO
META(robots=noindex): https://www.oru.se/nyheter/nyhetsarkiv/nyhetsarkiv-2014/?page=10
And so on…